
Java에서 XML을 파싱 하기 위해 사용되는 인터페이스들이다.
사용하는데 시각적으로 보여드리자면
대표적인 사용법은
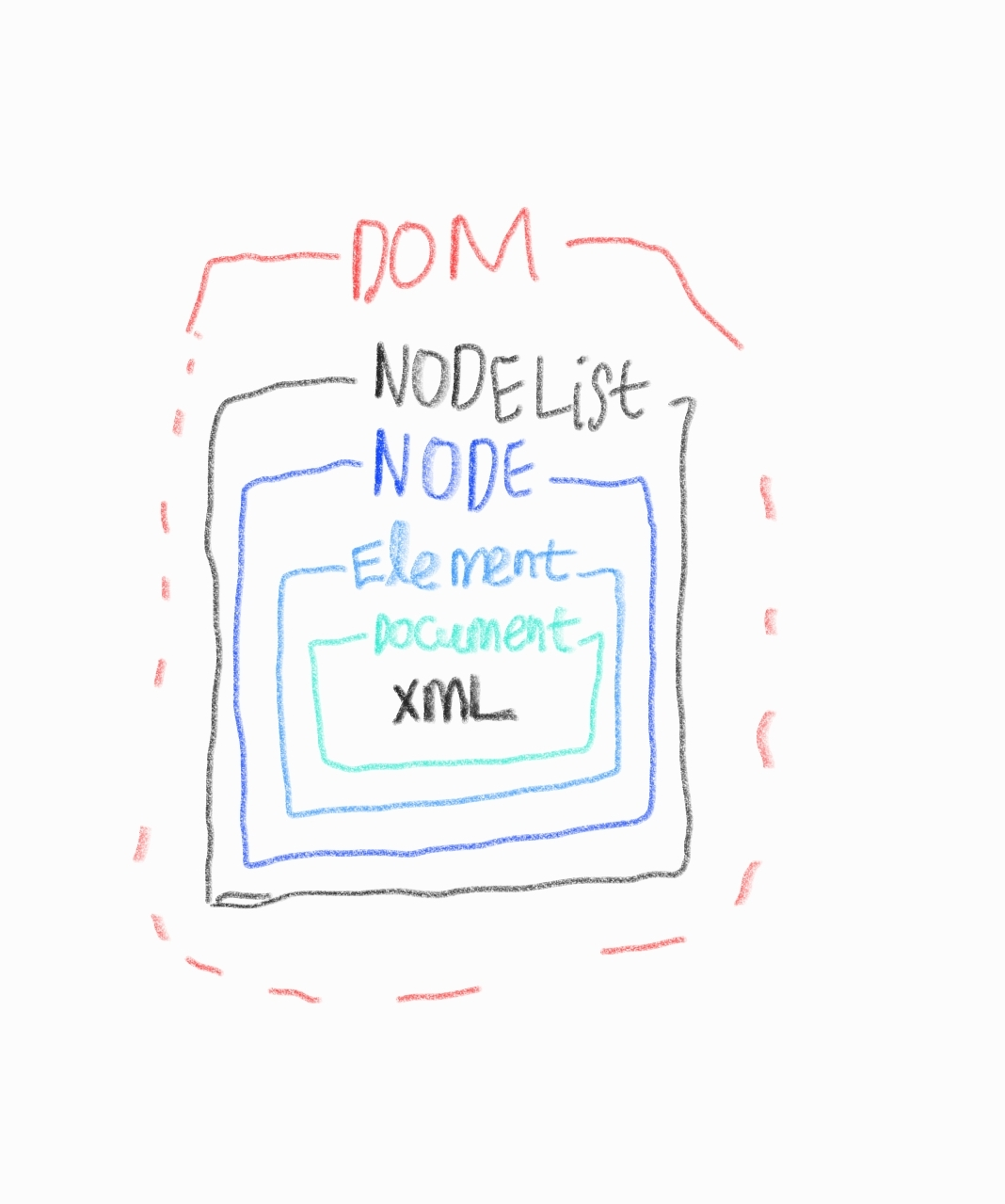
Node란
Node (Java Platform SE 8 )
cloneNode Node cloneNode(boolean deep) Returns a duplicate of this node, i.e., serves as a generic copy constructor for nodes. The duplicate node has no parent ( parentNode is null) and no user data. User data associated to the imported node is not carri
docs.oracle.com
xml 문서의 구성 요소 속성, 텍스트, 주석 등을 모두 노트로 간주.
노드들은 트리 구조로 구성되어 있으며 각각의 노드는 다른 노드와의 관계를 통해 서로 연결된다.
Java에서는 org.w3c.dom 패키지의 Node 인터페이스를 사용하여 xml문서의 노드를 처리하고 조작할 수 있다.
대표 메서드
getNodeName()
getNodeValue()
getNodeType()
NodeList 인터페이스
NodeList (Java Platform SE 8 )
The NodeList interface provides the abstraction of an ordered collection of nodes, without defining or constraining how this collection is implemented. NodeList objects in the DOM are live. The items in the NodeList are accessible via an integral index, st
docs.oracle.com
Node 객체들의 순서 있는 목록으로, 특정 노드 유형에 따라 필터링될 수 있다.
예시로 엘리먼트의 자식 노드들을 나열하는 데 사용한다.
XML 문서에서 여러 노드들의 집합이다.
대표메서드
item()
getLength()
Element 인터페이스
Element (Java Platform SE 8 )
setAttribute void setAttribute(String name, String value) throws DOMException Adds a new attribute. If an attribute with that name is already present in the element, its value is changed to be that of the value parameter. This value is a simple string;
docs.oracle.com
XML 문서에서 엘리먼트를 나타낸다. XML 문서의 구성요소로서 태그와 태그 사이의 내용을 포함한다.
<태그> 내용 <태그>
Element는 XML문서에서 태그로 표현되는 부분으로 나타내며, 사용하여 요소의 속성, 자식 요소, 텍스트 등을 조작할 수 있다.
주요 메서드
getAttribute()
getElementsByTagName()
getChildNodes()
Document 인터페이스
Document (Java Platform SE 8 )
The Document interface represents the entire HTML or XML document. Conceptually, it is the root of the document tree, and provides the primary access to the document's data. Since elements, text nodes, comments, processing instructions, etc. cannot exist o
docs.oracle.com
XML 문서 전체를 나타내느 객체를 제어하는 데 사용된다.
Document 인터페이스를 사용하면 XML 문서의 구조를 다루고, 필요한 정보를 추출하거나 수정할 수 있다.
대표 메서드
getElementsByTagName() // 특정 태그를 가진 모든 요소를 선택
createTextNode()
createElement()
순서(위에 사진 참고)
Document → Element → Node → NodeList
사용 예시
데이터 예시↓↓↓
<dataset>
<record>
<id>1</id>
<first_name>Wolfgang</first_name>
<last_name>Ayce</last_name>
<email>wayce0@vistaprint.com</email>
<gender>Male</gender>
<ip_address>51.164.31.182</ip_address>
</record>
<record>
<id>2</id>
<first_name>Alfi</first_name>
<last_name>Linnitt</last_name>
<email>alinnitt1@clickbank.net</email>
<gender>Female</gender>
<ip_address>224.237.144.37</ip_address>
</record>
<record>
<id>3</id>
<first_name>Jermain</first_name>
<last_name>Prati</last_name>
<email>jprati2@independent.co.uk</email>
<gender>Male</gender>
<ip_address>197.225.235.178</ip_address>
</record>
</dataset>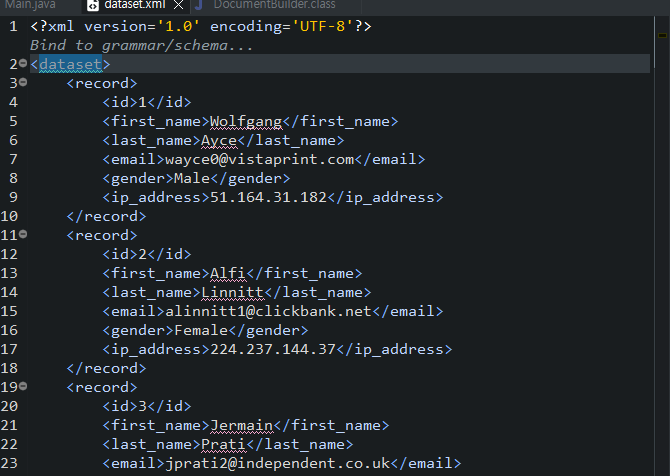
package testParsing;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;
import dto.MyObject;
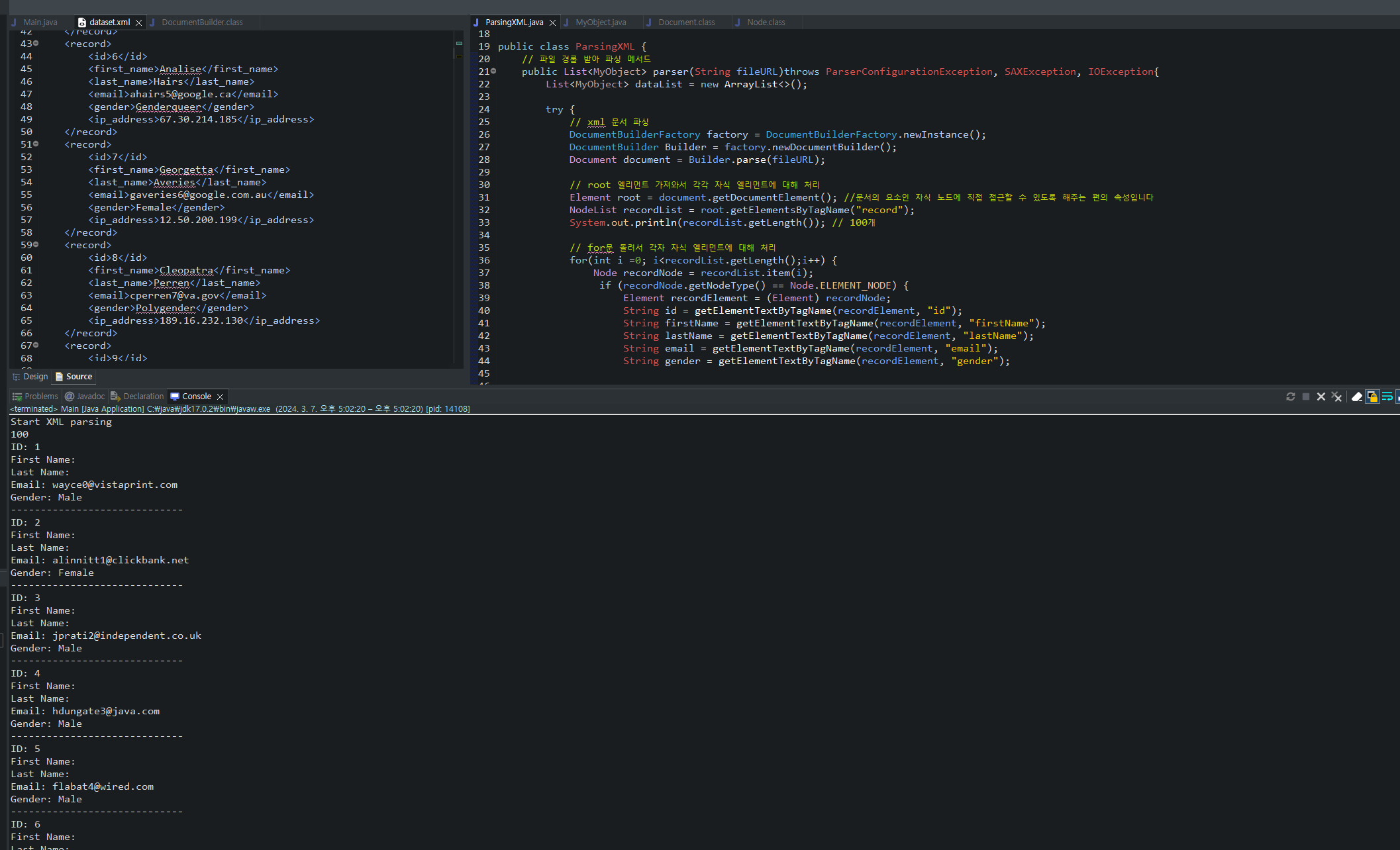
public class ParsingXML {
// 파일 경롤 받아 파싱 메서드
public List<MyObject> parser(String fileURL)throws ParserConfigurationException, SAXException, IOException{
List<MyObject> dataList = new ArrayList<>();
try {
// xml 문서 파싱
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder Builder = factory.newDocumentBuilder();
Document document = Builder.parse(fileURL);
// root 엘리먼트 가져와서 각각 자식 엘리먼트에 대해 처리
Element root = document.getDocumentElement(); //문서의 요소인 자식 노드에 직접 접근할 수 있도록 해주는 편의 속성입니다
NodeList recordList = root.getElementsByTagName("record");
System.out.println(recordList.getLength()); // 100개
// for문 돌려서 각자 자식 엘리먼트에 대해 처리
for(int i =0; i<recordList.getLength();i++) {
Node recordNode = recordList.item(i);
if (recordNode.getNodeType() == Node.ELEMENT_NODE) {
Element recordElement = (Element) recordNode;
String id = getElementTextByTagName(recordElement, "id");
String firstName = getElementTextByTagName(recordElement, "firstName");
String lastName = getElementTextByTagName(recordElement, "lastName");
String email = getElementTextByTagName(recordElement, "email");
String gender = getElementTextByTagName(recordElement, "gender");
// 데이터 출력
System.out.println("ID: " + id);
System.out.println("First Name: " + firstName);
System.out.println("Last Name: " + lastName);
System.out.println("Email: " + email);
System.out.println("Gender: " + gender);
System.out.println("-----------------------------");
}
}
}catch(ParserConfigurationException | SAXException | IOException e) {
e.printStackTrace();
}
return dataList;
}
// 요소의 내용을 가져오는 보조 메서드
private String getElementTextByTagName(Element element, String tagName) {
NodeList nodeList = element.getElementsByTagName(tagName);
if (nodeList != null && nodeList.getLength() > 0) {
return nodeList.item(0).getTextContent();
} else {
return ""; // 요소가 없으면 빈 문자열 반환
}
}
}
결과
주요코드 분석
// xml 문서 파싱
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); // XML 파서를 생성하기 위한 팩토리 생성
DocumentBuilder Builder = factory.newDocumentBuilder(); // XML 파서 생성
Document document = Builder.parse(fileURL); // 주어진 파일URL의 XML 문서를 파싱하여 Document 객체로 로드
// root 엘리먼트 가져와서 각각 자식 엘리먼트에 대해 처리
Element root = document.getDocumentElement(); // XML 문서의 루트 요소를 가져옴
NodeList recordList = root.getElementsByTagName("record"); // "record" 태그를 가진 모든 자식 요소를 가져옴
System.out.println(recordList.getLength()); // "record" 요소의 개수를 출력 (예: 100개)
// for문 돌려서 각자 자식 엘리먼트에 대해 처리
for(int i =0; i<recordList.getLength();i++) { // "record" 요소의 개수만큼 반복
Node recordNode = recordList.item(i); // 현재 순회 중인 "record" 요소를 가져옴
if (recordNode.getNodeType() == Node.ELEMENT_NODE) { // 현재 노드가 ELEMENT_NODE인지 확인
Element recordElement = (Element) recordNode; // "record" 요소를 Element 타입으로 캐스팅
String id = getElementTextByTagName(recordElement, "id"); // "record" 요소에서 "id" 태그의 텍스트 내용을 가져옴'코딩 > JAVA' 카테고리의 다른 글
| [Java] NIO 기반 파일 입출력 합치기 Kotlin 예제 (1) | 2024.08.29 |
|---|---|
| Java VSCode에서 게터세터(getter, setter) 쉽게 만들기 source action 자동생성 (22) | 2024.03.04 |
| java 자바에서 상속과 오버로딩: 객체지향 프로그래밍의 기초 (28) | 2024.02.08 |
| Java 객체지향 프로그래밍에서의 Getter와 Setter 활용: 데이터 관리의 핵심 (0) | 2024.02.06 |
| JAVA 메서드(method)의 이해와 활용 (0) | 2024.02.05 |
